
基于S1000D智能化IETM知识库的构建研究
1 引言
交互式电子技术手册(Interactive Electronic Technical Manuals,IETM)是当前武器装备保障信息化领域研究的一个热点,它在军事领域的应用能显著地提高武器装备的综合保障水平,增强部队的战斗力。美国国防部将IETM分为5级,现在所使用的IETM大多都是定位在第4级,投入使用的IETM几乎没有真正属于第5级的,即智能化的IETM。由于第4级的IETM仍然没有解决在检索信息时存在漏检、错检和输出冗余信息的问题,所以智能化的IETM就成为当前IETM迫切需要实现的目标。为了实现智能化IETM,首先必须构建智能化IETM的核心内容———知识库。
本文鉴于当前IETM长期存在漏检、错检和输出冗余信息的问题,针对军用飞机的领域知识,基于IETM的国际标准S1000D,引入本体的思想,构建一种智能化IETM系统的知识库模型,为以该知识库为核心的智能化IETM的实现奠定基础,提升信息检索的质量和效率,加快其应用产品的研发和维修反应能力,最大效率地提高武器装备的综合保障水平,增强部队的战斗力。
2 研究综述
本体是概念化的明确的规范说明,基于本体对知识库进行构建是提高知识的共享性、互操作性、可维护性和可重用性的一个有效途径。在文献[4]中详细描述了本体在构建知识库中起到的作用。
目前,国外已经有一些学者以本体为理论基础构建知识库,从而实现其应用系统的智能化,如美国德雷塞尔大学研究开发了一个名为医学信息抽取(MEDical Information Extraction,MedIE)的系统,目的是从大规模自由文本临床记录中抽取和挖掘出大量患乳腺疾病的病人信息。国内这方面的研究起步比较晚,目前比较有名的知识库研究有:中山大学的法律知识库的研究,中国科学院计算技术研究所的医学知识库等。然而国内外对交互式电子技术手册的知识库研究很少,可供实际操作指导的研究成果也相当缺乏。
3 智能化IETM知识库的构建
智能化IETM知识库的工作过程是:用户输入检索信息,系统把该检索信息提交到本体库中,本体库利用其语义扩展规则对该检索词进行推理扩展,据此推出一组与用户的检索对象具有语义关联的语义查询条件,然后把这组检索条件提交到数据库中进行匹配查询,然后返回查询结果。其过程如图1所示:
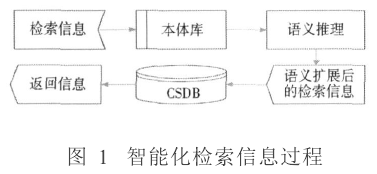
智能化IETM知识库的构建工作主要分为两个部分:
(1)构建符合国际化标准S1000D的IETM数据库用于存储其应用领域的数据集合,如图1的CSDB部分所示。
(2)建立其应用领域的本体库,并对其构建的本体库进行语义推理,如图1中本体库和语义推理部分所示。
3.1 IETM数据库
为了更好地实现数据共享,IETM的数据表示需要遵守一定的领域标准。本文选择S1000D标准,它的一个重要特征是为IETM的制作提供一个开放系统表述方法,以数据模块(Data Module,DM)组织技术信息,以公共源数据库(Common Source Data Base,CSDB)管理信息对象。公共源数据库和数据模块作为S1000D中的两个核心概念,用来保证IETM实例间的信息共享和交换。其数据模块的结构如图2所示。
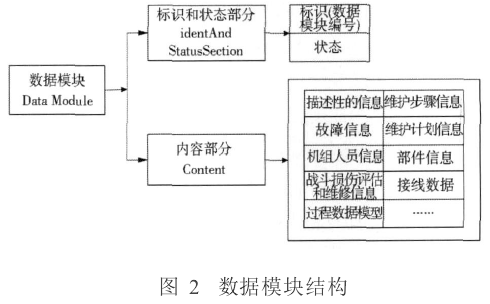
根据S1000D标准制作的DM以离散的XML文档存在,考虑到可操作性和安全性,系统采用SQL Server2005来存储和管理DM。SQL Server2005对XML有很好的支持,增加了XML文档数据类型,在字段中可以直接存储XML文档。本文在数据库中创建数据表分别用于存储数据模块的标识状态部分和内容部分的描述性信息(Descriptive Information)、过程信息(Procedural Information)、故障信息(Fault Information)、维护计划信息(Maintenance Planning Information)、机组成员信息(Crew/Operator Information)、部件信息(Parts Information)、战斗损伤评估及修复信息(Battle Damage Assessment and Repair Information)、配线数据信息(Wiring Information)、数据处理模块(Process Data Module)、技术资料库(Technical Information Repository)、集成数据模块(Container Data Module)。数据库表中的每条数据是通过标准结构的唯一性数据模块代码(Data Model Code)来标识和访问。把DM根据内容拆分存储在不同的数据表内,这样可以提高数据操作和维护的效率。所建的数据表关系如图3所示:
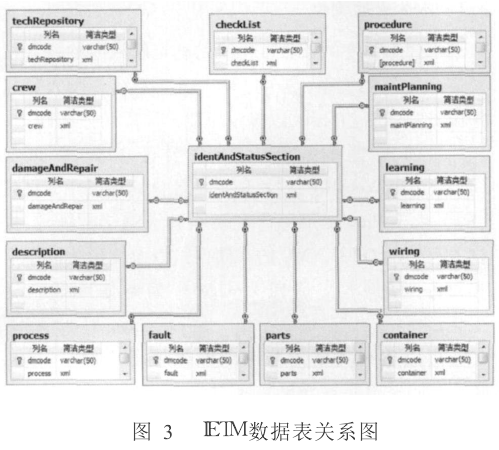
表中字段“DMCode”对于数据库中数据类型为XML的字段,本文根据S1000D里的Schema为每个表里这样的字段向SQL Server数据库中注册相应的XML Schema,在注册之后,每个XML数据类型的字段必须严格遵守Schema结构,否则在向表中添加数据时就会返回一个错误信息,保存失败。
例:对于表ident And Status Section的创建:
(1)向数据库中注册ident And Status Section的XML Schema;
CREATE XML SCHEMA COLLECTION ident Schema AS
N`<? xml version="1.0"encoding="UTF-8"?>
<xs:Schema xmlns:xs="http://www.w3.org/2001/
XML Schema"
Target Name space="http://ident Schema"element Form-
Default="qualified"
attribute Form Default="unqualified">
<xs:element Name="ident And Status Section"type="ident
And Status Sectiontype"/>
<xs:complex type Name="ident And Status Section type">
<xs:element ref="DM Address"/>
……
</xs:element>
</xs:Schema>'
(2)使用第(1)步创建的identSchema创建符合其数据规范的表;
CREATE TABLE ident And Status Section
(dm Code varchar(50)PRIMARY KEY,ident And Status Section XML
(ident Schema))
(3)建立与其他表的主、外键关系。
3.2 本体库的构建
构建本体库的核心工作就是确定领域内的概念以及概念之间的关系,整个过程中需要系统开发人员与领域专家的密切合作,以确定所建本体库的正确性。
目前,构建本体库的工具主要有OilEd、Protégé、Onto Edit和WebODE,这4种工具各自的特点。由于Protégé可免费下载,并配有诸多的插件,提供RDF(s)、OWL、XML的存储格式以及图形化的用户界面等,因此本文选择Protégé作为本体库的构建工具。
可以实现本体语言推理的推理机主要有:Jess、Racer、Jena,因为Protégé有专用接口可引入Racer,可以直接在Protégé中实现概念基本关系的语义推理,所以本文在构建本体库的时候选择使用Racer,可以判断本体库内概念的一致性,便于及时发现错误,从而减少构建本体库的工作量。因为Jena的语义推理规则是可以自定义的,从而实现了在语义推理规则上的灵活性和全面性,所以在检索系统进行语义推理时选择Jena作为语义推理机。
从语义上讲,本体中的基本关系共有4种:part-of、kind-of、instance-of和attribute-of。实际构建本体过程中,概念之间的关系不仅限于这4种,可根据领域的具体情况自定义一些关系。
对于创建好的*.owl文本,可通过一定的规则进行推理。对上述4种基本关系,一般通用的推理机都可实现其语义上的推理。但是对于自定义的概念关系的推理,需要自己去定义规则文件,按照Jena Generic Rule Reasoner的规则编写规范,存储为*.Rules作为推理机自定义规则的输入文件。其语义推理模型的程序结构如图4所示:
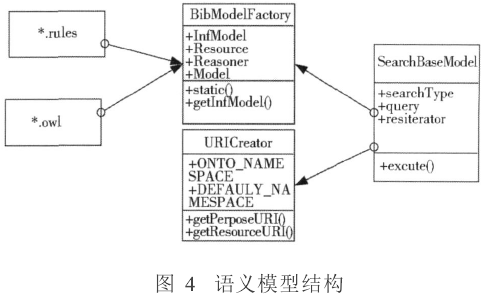
其中Bib Model Factory类用于配置推理机的规则库和本体库,返回inf Model模型;Search Base Model调用Bib Model Factory的inf Model并按三元组范式检索模型;URI Creator工具类用于统一定义命名空间,为检索关键词返回规范的URI值。
3.3 IETM数据库与本体库的映射
在进行信息检索时,可利用三元组的形式引导用户输入检索条件,根据检索条件构成的SPARQL语句以及预定义的规则文件可以得到一个以检索条件为基础的语义关联树。用户根据需要选择合适的树节点,即选择最终的检索条件。由于IETM信息是以结构化文档的方式存储,所以可以选择检索信息的域,从而确定CSDB中的数据库表。对于所选的数据库表,还可进一步选择其数据库表XML Schema的节点(S1000D提供的每个Content Section的Major elements),根据用户最终确定的检索条件在选择的节点内检索匹配内容。
4 实例设计
依据《国防科技词典》以及领域专家的协助,对于军用飞机领域的概念进行抽取、描述并分析概念之间的关系,选择在军用飞机领域里最重要的概念“军用飞机”作为该本体库的顶级概念,然后是“飞行员”、“飞机名称”、“飞机结构”、“飞机性能指标”等。
在第3.2节中提到的4个基本关系的基础之上,需要增加一些Properties,用于更好地表示概念关系,部分如下:
(1)因果关系:A引起B,则B造成了A。在Properties里添加“has Caused”和“is Caused Of”,设置它们的Domain和Range,并把这两个属性set Inverse Properties and Transitive Property,这样就可以在语义上实现逆推和传递。
(2)实体/定位关系:A放在B处,则B处有A。在Properties中添加“has Location”和“is Location of”,把它们set Inverse Properties,并设置它们的Domain和Range。
(3)代理/对象关系:A操作B,则B被A操作。在Properties中添加“has Operator”和“is Operator Of”,把它们se tInverse Properties,并设置它们的Domain和Range。
(4)执行/方法关系:A执行B,则B被A执行。在Properties中添加“has Manner”和“is Manner Of”,把它们set Inverse Properties,并设置它们的Domain和Range。
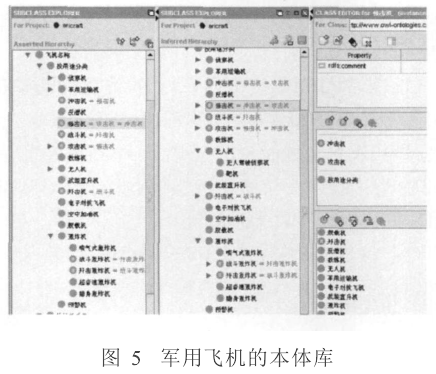
本文使用Protégé进行本体库的构建,并引入Racer Pro进行本体库内概念一致性检验,从而确保所建本体库的正确性,其结果如图5所示。其中最左边一列是本体的概念集,中间部分为推理的结果,最右边一列是对相应的概念进行编辑。
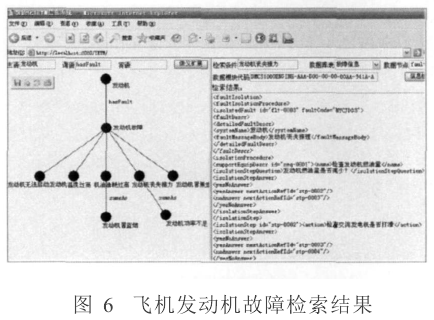
以检索飞机发动机的故障为例,首先输入检索词(主语、谓语、宾语不需要全部填写)进行语义扩展,在执行语义扩展之后,可得到其检索信息的语义关联树,如图6中左页面所示。双击选择“发动机丧失推力”节点,输入数据模块编码并选择检索域和XML节点(可选项),便可得到图6中右页面所示的结果(未加样式的表示)。本例中所用的SPAQL语句和部分规则如下:
SPAQL语句:
PREFIX vcard:<http://www.nwpu.edu.cn/IETM/Ontolo-
gy1237340150.owl#>
SELECT ? oWHERE
{vcard:发动机vcard:has Fault ? o.}
规则:
[:has Fault
(?a http://www.nwpu.edu.cn/IETM/Ontology1237340150.owl
#?hasFault?b),
(?c http://www.w3.org/2000/01/rdf-Schema#sub Class Of?b),
->(?a http://www.nwpu.edu.cn/IETM/Ontology 1237340150.owl#?hasFault?c)]
[:hasFault
(?a http://www.nwpu.edu.cn/IETM/Ontology1237340150.owl
#?hasFault?b),
(?c http://www.w3.org/2002/07/owl#same As?b),
->(?a http://www.nwpu.edu.cn/IETM/Ontology 1237340150.owl#?hasFault?c)]
…
5 结语
IETM的知识库是实现IETM智能化的基础和前提,本文以S1000D4.0为创作标准,结合本体的思想,针对军用飞机领域的知识构建了一个知识库模型,该知识库结构清晰、可操作性强,因此可以对智能化IETM的实施提供可行的指导。