
基于Lucene的IETM系统检索器的设计实现
交互式电子技术手册(IETM)作为支持武器装备使用与维修的重要保障资源,是装备保障信息化建设的发展趋势。IETM的基本功能之一是信息的快速定位。如何从大量的技术文档中快速、准确、全面地检索出用户所需的信息,成为衡量IETM系统性能的一个重要指标。IETM系统中的技术资料数量庞大,往往有几十种,上百册,几万页。通过传统的数据库全文检索进行单一的文字匹配时,往往会导致查询结果的冗余度大。不仅查询结果会有几百甚至数千个,而且查询结果的排列是无序的,无法满足用户快速获取当前任务所需的技术信息的要求,因此,设计高效的检索器,提高技术信息的查准率,是IETM系统设计的关键性问题之一。
1 基于S1000D标准的IETM
ASD/AIA/ATA S1000D《基于公共源数据库的技术出版物的国际标准》是目前国际上IETM应用最广泛的标准之一。S1000D采用模块化设计和单一数据源管理思想,将技术内容分解为数据模块(Data Module,DM)。DM是由装备或其部件的描述、程序、操作数据组成的独立信息单元,按照特定的DTD/Schema对技术数据进行标注,生成SGML/XML文档,存储在公共源数据库(Common Source Data Base,CSDB)中,通过数据模块代码(Data Module Code,DMC)标识。全部数据应无冗余存储,并可通过代码、信息类型或其他元数据,以目录或搜索的方式从CSDB中检出。
DM按照其内容结构的不同,分为9种信息类型。每种类型的信息都有详细的文档模式文件(Schema)来约束和验证文档的内容结构。标记规范,信息表述精确,为信息查询和信息之间的关联奠定了基础。
2 IETM系统的检索功能需求
S1000D中定义,IETM除了能按照装备系统/子系统/设备(SNS)的层次结构目录直接访问技术信息以外,还应提供关键词检索、自定义逻辑检索、全文检索、跨库检索、上下文检索,以及适用性过滤等检索功能。IETM检索过程可以描述为:用户提交查询条件,检索系统根据该查询条件在所有的DM集合中检索出最符合用户需求的信息。由于用户需求是多样化的,不同的用户可能提交相同的检索词,但关注的信息却不尽相同;不同的用户也可能提交有差异的检索词,但实际需求的却是同一条信息。例如,同样是“千斤顶”,管理人员X关心的是哪些工作要用到它,以便于订货;地面设备保障人员Y需要其结构图,以便于更换零件;地勤人员Z则想了解“千斤顶”的使用方法。根据信息类型的划分,人员X应该在程序性信息DM的“所需设备”元素(supequip)中查找,如图1所示;人员Y应该在图解零部件目录DM的“图形”元素(figure)中查找;而人员Z则应该在描述性信息DM的“段落”元素(para)中查找。
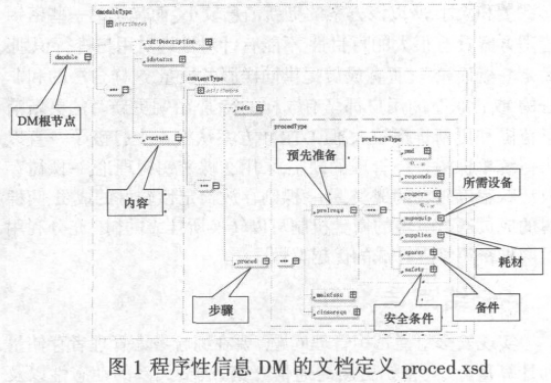
因此,为了提高技术信息的查准率,检索系统应该根据不同信息类型的文档结构,通过预先定义可检索信息的查询路径,来准确地表达装备保障人员的真实意图。表1为某型飞机IETM系统中部分查询项与元素路径的对应关系。
3 Lucene开源全文检索工具包
传统的数据库检索技术在处理海量数据的模糊查询时,不仅信息冗余度大、速度慢,而且无法体现信息相关度方面的信息。近年来,Lucene以其开放源代码的特性、优异的索引结构、良好的系统架构获得越来越多的应用。
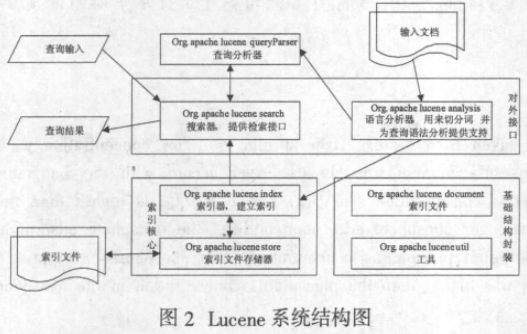
Lucene是Apache Jakarta家族中的一个开源项目,是一个基于Java的全文检索引擎工具包,提供了一组信息检索的函数库。它提供了8个模块的源代码,建立索引时,Org.apache.lucene.analysis对外部输入的文档进行切分词,在Org.apache.lucene.document中定义关键字和文档的对应关系,加入到Org.apache.lucene.index构建的倒排索引系统中,由Org.apache.lucene.store完成索引文件的存储。检索时,Org.apache.lucene.queryParser对查询语句进行分析,并定义查询条件的逻辑运算规则,Org.apache.lucene.search创建检索器,在索引文件中进行快速查询,并根据文档相关度返回结果。Lucene的系统结构如图2所示。
4 IETM系统检索功能的实现
Lucene特殊的索引结构,不仅可以提高检索效率,而且索引文件格式与平台无关,任何格式的数据源,只要能转化为文字,就可以用Lucene建立索引并进行检索。本文根据表1中定义的查询项及其内容路径,通过XPATH语句抽取出数据模块XML文档中的内容,建立索引,从而实现精确查询。
4.1建立索引
Lucene有两个最重要的索引类:Document和Field,类似数据库中的表和字段。其中,Document类表示数据源的集合,用来提供待索引的数据;而Field类主要用来表示数据源的各种属性。因此,IETM系统中,要根据预先定义的查询方式对技术资料的XML文档进行解析,将每个查询项的信息抽取出来,分别创建Field类,添加到Document中,生成索引文件。
4.2信息检索
Lucene中基本的检索类包括IndexSearcher类和Query类。Query类封装了查询词、查询字段和语言分析器,可以提供丰富的查询模式,包括模糊查询、语义查询、短语查询、范围查询、组合查询、前缀查询等,交由IndexSearcher查询,并将结果返回到Hits类中。在检索的结果比较多时,Hits对象并不会真正把所有的结果全部取回,默认情况下是保留匹配度最高的前100个记录。主要代码如下:
IndexSearcher searcher=new IndexSearcher (IN-DEX_STORE_PATH);
MultiFieldQueryParser parser=new MultiFieldQuery-Parser(new string[]{"paratitle"},new ChineseAnalyzer());
Query query=parser.Parse(keystring);
Hits hits=searcher.Search(query);
Document doc=h.Doc(i);
StringBuilder sb=new StringBuilder();
sb.Append("<entries>");
for(int i=0;i<hits.Length();i++){
Document doc=hits.Doc(i);
sb.AppendFormat("<option url='{0}' dmtitle='{1}'/
>",“card.aspx?dmc=”+doc.Get("dmc"),doc.Get("dmtitle"));}
sb.Append("</entries>");
4.3检索界面

本文采用ASP.NET Ajax框架,通过客户端调用Web Service的编程模式实现了检索功能,用户界面如图3所示。预先定义的检索项包括段落、步骤、标题、工具/设备、耗材、备件、表格、图形、警告、注意、注等。用户在下拉框中选择检索项,并在文本输入框中输入检索文字。开始查询后,客户端发出HTTP请求,在WebService中实现检索,并将查询结果返回客户端。客户端通过JavaScript解析,根据查询结果生成显示列表。
整个过程中,前后台之间只进行数据的传输,在不更新整个页面的前提下进行数据的刷新,减少了不必要的数据传输量,系统响应迅捷,用户体验好。
5 结束语
本文设计的IETM检索器已在3种机型的IETM系统中使用,检索速度快,精确度高,查询结果按相关度排序,能够显著提高IETM有关提供当前任务所需全部信息的“聚焦”能力。
本文作者创新点:针对IETM系统的检索需求,提出并实现了根据不同信息类型的文档结构,利用预先定义的查询路径表达查询意图,提高技术资料查准率的方法。