
基于多元数据图表示的可视化模式识别
概 述
模式识别是通过对象的观测数据实现其分类和识别的一门技术。现代统计模式识别以所研究的数据满足一定的统计分布规律(一般为高斯分布)为前提假设。然而现实问题研究中存在大量不满足任何已知统计模型(非高斯)情况。文献[2]提出广义统计范畴下的非统计模式识别概念,主张在进行模式识别研究之前进行统计假设检验,根据实际情况采取合适研究方法,避免统计方法盲目滥用而造成的信息失真。对于非高斯信息处理,文献[3]和[4]提出高阶统计量或分数低阶统计量作为工具进行信号处理或信息分类;文献用有限正态混合分布模型来描述非高斯随机信号的统计规律;文献进行了非统计原理在人脸表示和识别的应用研究。多元数据多元图表示是多元变量分析中的一项重要技术,通过可视化分析可能很容易发现一些数据的规律,这些规律不一定属于已知的任何统计规律。目前,国内外专家在多元图表示、可视化分类等方面做了很好的研究工作,多元可视化成为科学可视化的一个重要分支。
本文基于多元数据多元图表示提出对非高斯分类信息进行可视化模式识别,通过人机交互可视化分析进行特征提取优化研究,并通过算法实现了多元数据多元图可视化分析过程的客观化和自动化,最后基于UCI数据对该方法进行了数据实验。
1 多元数据图表示
多元数据图表示包含很多不同方法,如散点图、轮廓图(平行坐标图)、多维径向坐标图(星点、雷达图)、星座图和脸谱图等,这里简单介绍实验中用到的几种。
1.1散点图
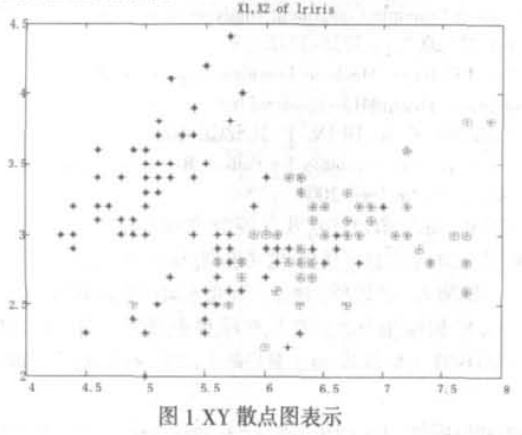
散点图(scatter plot)就是将多维数据以平面或空间中的点来表示,最常用的是二维数据在平面直角坐标平面内表示的情况,称为直角散点图或XY散点图。如图1为Iriris数据集前两个变量特征的XY散点图。XY散点图能够描述的是包含两个变量的二维数据,在使用这种方法描述高于二维的多维数据时,常用散点图矩阵来表示。散点图矩阵可以看作一个大的图形方阵,其每一个非主对角元素的位置上是对应行的变量与对应列的变量的散点图,而主对角元素的位置上是各变量名,这样借助散点图矩阵能够清楚地看到所研究的多个变量两两之间的相关关系。
1.2轮廓(平行坐标)图
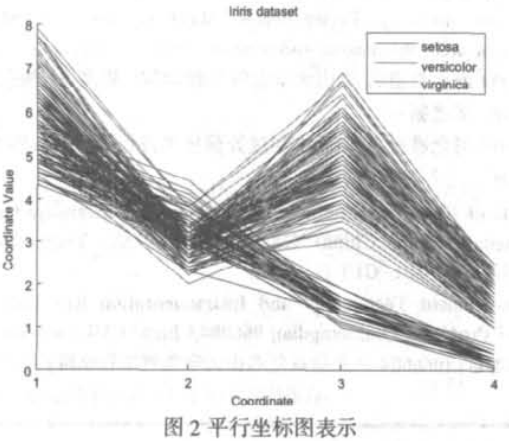
轮廓图(Profile plot)也被称作平行坐标(Parallel Coordinates),它利用相互平行的多条等距离轴将m维欧式空间的点将映射到2维平面上的一条曲线。如图2为Iriris数据集的平行坐标图表示。每条轴对应多元数据的一维,每个数据项显示为一条折线,与每个轴相交于相当于参考维值的那一点。它通过在一张平面图上展现数据的多个变量,实现多元数据表示从高维空间向二维平面的映射,便于研究者对多元数据进行观察比较,以便迅速掌握多元信息间的相互关系。
2基于多元图表示的变量模式类分立特性分析
在模式识别的分类研究中,各类别样本数据在多元图表示中用不同颜色或类型的点或线条表示,那么根据多元图观察很容易定性分析变量的类别混杂性质。显然若在对应变量上模式类的分立特性越好,那么基于该变量特征的类分性能越好。变量的模式类分立特性分析可作为评价样本在变量上线性可分性的度量。
如图2所示,应用平行坐标图表示技术可以实现单变量的模式类分立特性分析。文献[9]对一组蔬菜油数据进行了基于单变量模式类分立特性分析的主成分特征提取优化研究,然后用多元数据散点图表示方法对优化前后的特征结果的分类效果进行了定性的观察分析评价,初步得出单变量模式类分立特性分析有利于改善样本分类效果的研究结论。
应用散点图或散点图矩阵(如图1所示)可以实现二变量的模式类分立特性分析。当然三维散点图或散点图矩阵可以实现三变量模式类分立特性分析,但由于存在观察视角的选择问题(不同视角可分性可能不同),分析过程引入更多的主观和随机因素。至于高于四维的变量模式类分立特性分析目前用多元图表示方法尚无解决方案。
3单变量模式类分类特性人工可视化分析的算法实现
采用多元数据多元图表达技术进行变量分析过程中,依据是人的直观观察以及主观经验判断,这对于信息分类过程客观化是不利的,同时人工参与大大降低了分类效率。下面对基于各类数据混叠多元图分析的变量选择过程用算法实现。
研究对象的不同状态在测量中表现为不同的样本数据,每一种具体状态称为对象的一种模式。具有一定共同特征的群体组成相应模式类,模式分类工作是把各个表达为具体样本数据的模式归入其对应模式类中。
样本变量的模式类分立特性是表征不同模式类样本的变量数值分布混杂程度的一个性能指标。类间重叠系数是为了实现自动分析样本变量的模式类分立特性的一个工具参数,用符号σ表示,σij表示样本第j个变量的第i模式类的类间重叠系数,表达式为

其中N其他表示处于i模式类j变量数据分布区间之内其它模式类的样本数,Ni表示i模式类j样本数。σj表示样本第j个变量的综合类间重叠系数,对于m类问题表达式为

其中N其他表示处于i模式类j变量数据分布区间之内其它模式类的样本数,N表示样本总数。以σij和σj为元素组成样本集的类间重叠系数矩阵,表示为

σij的值表征多元信息第j个变量对于第i个模式类的分立特性,σij的值越靠近0表明第j个变量对于第i个模式类的分立特性越优异。σj表征多元信息第j个变量的所有模式类的综合分立特性,σj的值越靠近0表明第j个变量的综合分立特性越优异。
虽然高于四维的变量模式类分立特性分析通过多元图表示很难实现,但可以用算法实现变量的高维模式类分类特性分析,此处不赘述。
4 数据实验
下面进行基于多元图表示原理(基于多元数据平行坐标表示和类间重叠系数矩阵的单变量模式类分立特性分析)的式识别应用实验研究。
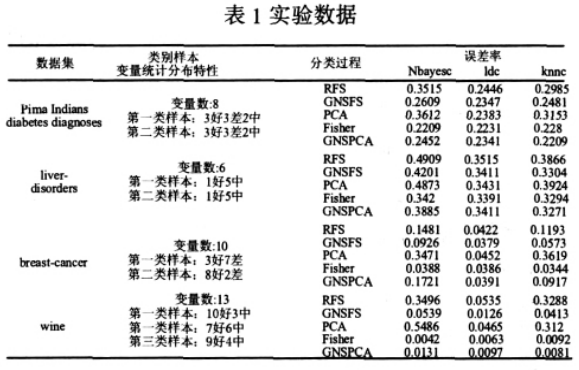
实验中采用UCI机器学习数据库中的Pima Indians diabetes diagnoses、liver-disorders、breast-cancer、wine数据集作实验数据,其中Pima Indians diabetes diagnoses为一组糖尿病断数据,它由包含8个变量的768组数据构成2类识别样liver-disorders为一组肝功能紊乱临床检验数据,它由包含7变量的345组数据构成2类识别样本;breast-cancer为关于腺癌症的检验数据,它由包含9个变量的683组数据构成2识别样本;wine为酒类数据,它由包含12个变量的178组数构成3类识别样本。工具软件主要应用Matlab7.0和PRTool4工具箱进行对比实验研究.
实验过程如图3所示。首先对每个实验数据集的类别样进行统计分布特性分析,本实验中应用MATLAB工具(normplot)对类别样本的高斯分布做定性分析,记录结果,作为分类结果析的参考条件。然后对实验数据集分别在各种实验设计不同件下进行分类实验,记录每次实验结果,结果采用20%(随机选80%为训练集,20%为测试集)10次交叉检验误差估计作为对评价检验指标。实验设计条件指数据分类前采用的不同特征取方法,包括随机特征选择(RFS)、基于多元图表示原理的非计特征选择(GNSFS)、主成分特征提取(PCA)、Fisher特征提(Fisher)和基于多元图表示的非统计优化的主成分特征提(GNSPCA),分类器选择基于统计方法的分类器选择标准概率度基准的贝叶斯分类器(nbayesc)和标准概率密度基准的线性类器(ldc),基于非统计方法的分类器选择k近邻分类器(knnc)。最后对实验结果进行对比分析,总结实验结论。

实验数据结果如表1所示,由实验结果分析可见,主成分特征提取方法进行分类所得的误差率普遍较高,甚至高于随机选择特征方法,这说明在模式分类问题研究中,对主成分特征选择方法进行基于变量模式类分立特性分析的优化研究是必要的;而基于多元图非统计(变量模式类分类特性分析)优化后(GNSP-CA)的分类误差率相对优化前(PCA)具有一定改善;基于多元图表示原理的非统计特征选择(GNSFS)方法相对于随机特征选择(RFS)分类结果要好,这一点不必解释,因为GNSFS方法实质上就是RFS方法结合人工观察筛选的特例。综上,本实验中基于多元图表示原理的非统计方法对于分类问题研究具有正面影响。
5 结论
基于多元数据图表示的非统计模式识别技术具有的可视化特点,通过数据可视化、过程可视化和结果可视化途径有利于模式识别研究过程中的人机交互和研究问题理解,是非高斯信息模式识别的有力工具。可视化人机交互过程的算法实现,有利于克服人工可视化分析主观性强和效率较低的问题。本文作者的创新点是通过多元数据多元图表示将可视化引入模式识别研究领域,实现了机器学习和视觉分类的互补和协作。
参考文献:
[2]朱兴动,黄葵,王正.PD F 文档化 IE TM 应用实例研究[J].航空电子技术, 2003,34(3):43;
[3]王学奇,肖 明 清,周 越文. 交互式电子技术手册及其应用研究[J].2002, 28(5):227;
[4]郭建胜,刘雪峰.基于 W eb 计算模式的交互式电子技术研究[J].2004,30(4):145;